검색엔진 작동원리 설명에 앞서 검색엔진 종류부터 살펴 보면 크게 아래와 같이 나눌 수 있다.

검색엔진 종류
검색엔진 최적화(SEO)와 검색엔진 마케팅(SEM)에 대한 주제를 다룬다면 크롤러 기반의 검색엔진에 대한 것이라 생각하면 된다. 그럼으로 검색엔진 작동 원리에 대한 설명 역시 크롤러 기반의 검색엔진 기준으로 설명한다.
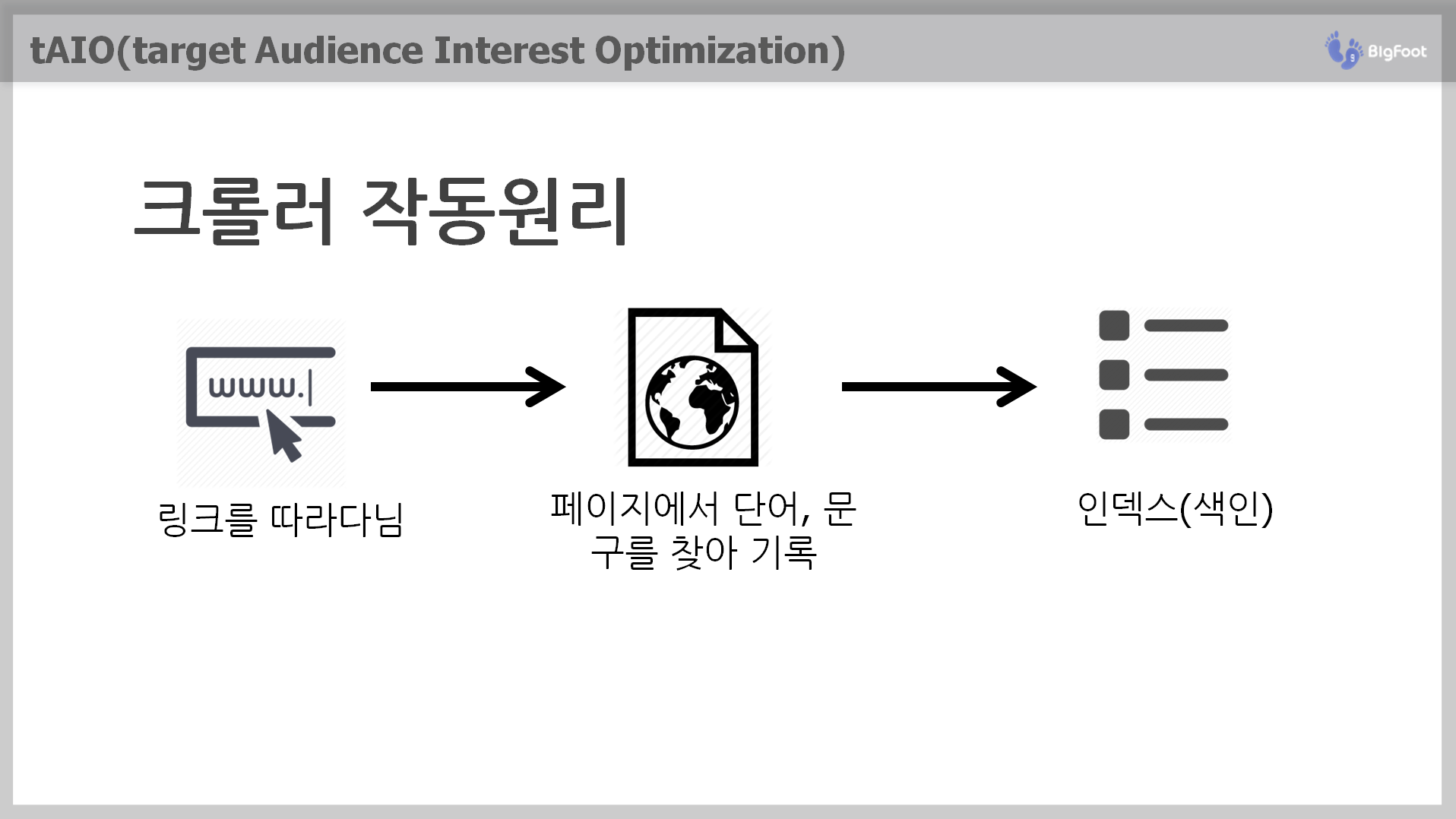
구글 검색을 예를 들어 보면 크롤러(스파이더)는 URL을 따라 웹 페이지를 이동한다. 출발점이 되는 URL은 구글 검색에 등록 신청한 웹 사이트, 야후 디렉토리, 오픈 디렉토리, ISP 업체에서 제공하는 서버 목록 등에서 가져 온다.
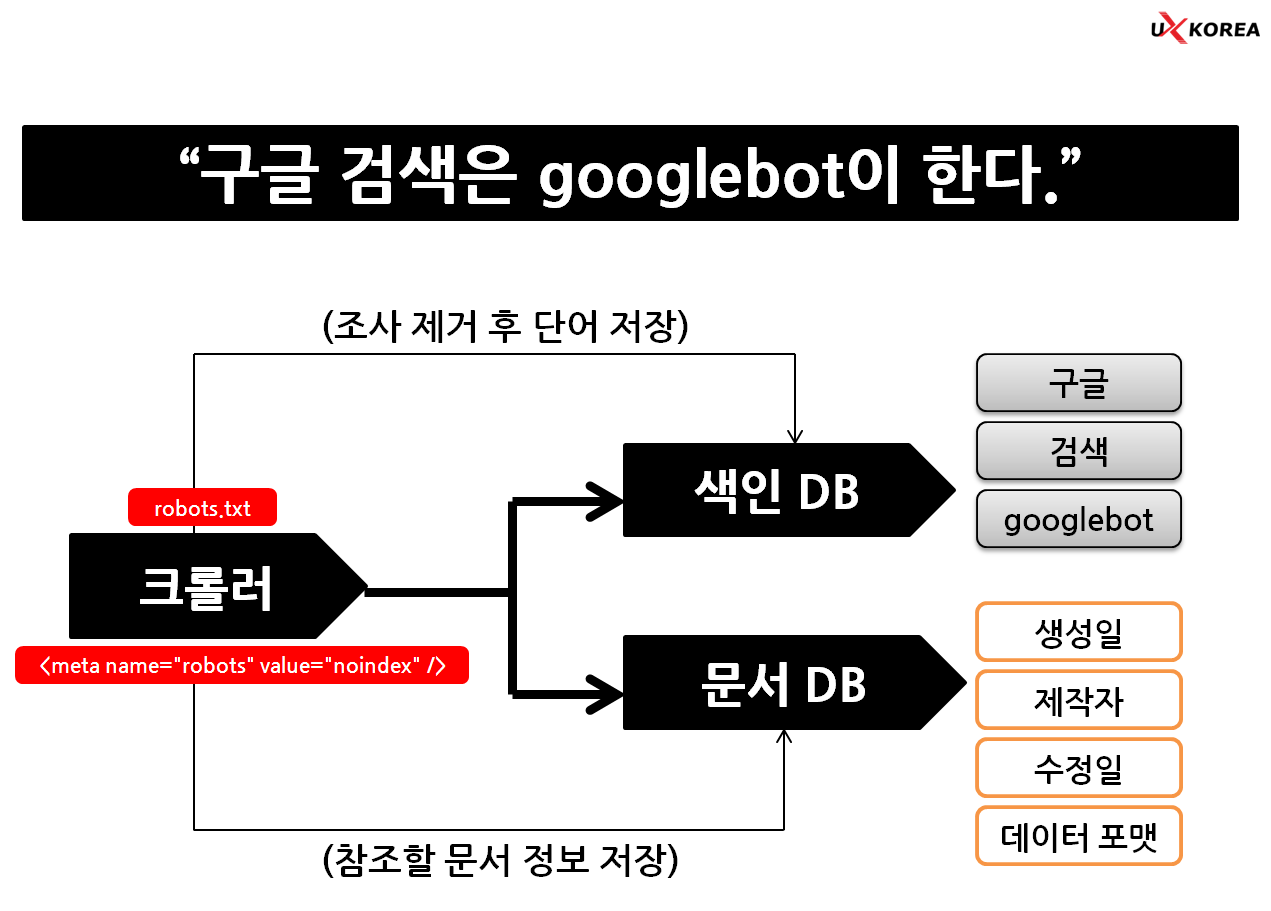
검색엔진은 링크(link)와 텍스트(text) 기반 인식 기본이다. 크롤러가 방문한 웹 페이지에서 새로운 링크(link)를 발견하면 웹 서버에 데이터 정보를 요청하고 이때 웹 서버는 검색엔진에게 웹 페이지 정보를 보내는데 이것이 바로 메타태그가 포함된 사이트 정보다.
검색엔진(크롤러) 인덱스 프로세스
크롤러는 그렇게 추가로 수집한 URL에서 단어와 문구를 분리하여 저장한다. 저장 과정에서 각 단어와 문구(쿼리)에 가중치(weight)와 연관도(relevance)를 부여 하고 최종 결과 값을 인덱스(색인)한다.
검색자가 검색창에 검색어를 입력하면 그 때 필요한 것을 끄집어 내는 것이 아니라 검색엔진이 미리 구축해 두었던 인덱스(색인)을 검색하는 것이다. 이 과정이 없으면 검색 결과를 얻기까지 엄청난 시간이 소요된다.
구글 검색엔진 작동 원리
검색엔진의 인덱스는 주기적으로 업데이트 되는데 가중치에 대한 기준과 업데이트 주기는 검색엔진마다 다르다. 또한 검색 순위 산정 기준에 대해서는 구체적으로 공개하지 않는다. 다만 검색엔진 구현 원리에서 생각해 보면 큰 줄기 정도는 알 수 있다.

검색엔진 검색순위 결정 원리
웹 페이지에 등장한 단어(키워드) 출현 빈도(회수)에 가중치를 주는 검색엔진, 문서 상단에 나타난 키워드에 가중치를 주는 검색엔진, 그리고 네이버처럼 검색문구(쿼리)가 접수되면 특정 형태소에 가중치를 주는 경우도 있다. 참고로 구글은 200여 개 항목으로 년 평균 500회 정도 업데이트하는데 거의 매일 크고 작은 순위변화가 있다.
네이버 라이브 검색은 기존의 통합검색에서 사용 되었던 형태소 중심의 순위 결정에 3가지 요소를 추가한 개념이다.
▲ 기존의 클릭정보 외에 사용자의 좋아요, 댓글 등과 같은 사용자의 액티브한 정보를 피드백 정보로 활용하는 ‘라이브 피드백(LIVE Feedback)’, ▲ 관심사가 유사한 사용자 네트워크 정보를 활용하는 ‘라이브 위드니스(LIVE Withness)’ ▲ 장소, 시간, 날씨 등 사용자의 현재 상황에 따른 맥락을 고려하는 ‘라이브 콘텍스트(LIVE Context)’ 등 사용자가 정보를 요구한 지점의 맥락을 분석하고 사용하는 기술을 고도화했다.
라이브 검색에도 형태소가 여전히 의미 있게 작용할 것이란 예상은 네이버가 최근 확장한 해시태그(#)를 보면 짐작할 수 있다. 그리고 더 확신을 갖게하는 자료로는 이번 컨퍼런스에 참석했던 블로터 기사를 보면 알 수 있다.
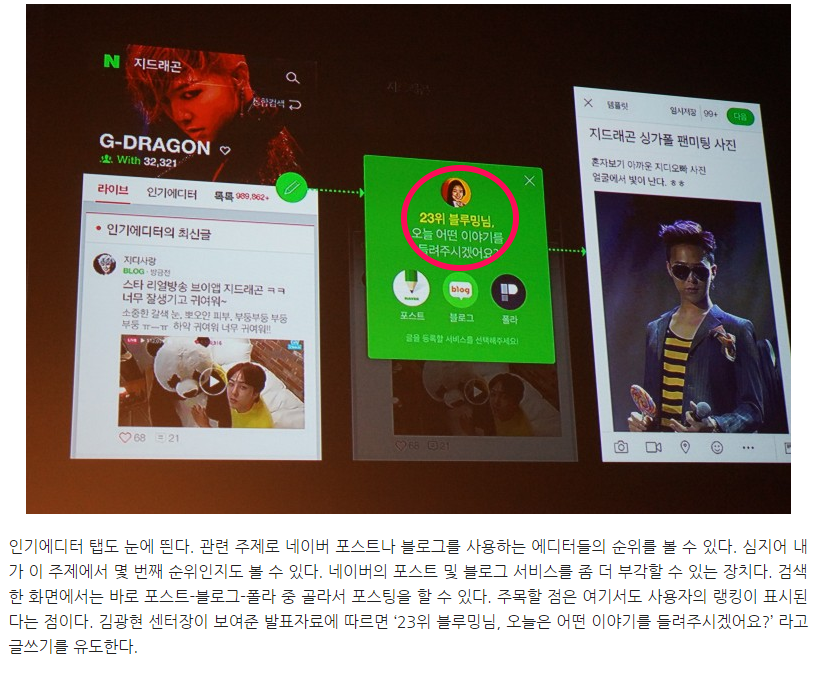
네이버 라이브 검색의 랭킹 일종의 평판 랭킹 시스템이라고 한다.
인기 에디터와 라이브 팬 랭킹에 눈이 가지 않을 수 없는데 기사 말미에 이런 내용이 있다.
라이브 위드검색은 단순히 방문자 수, 이웃 수, 검색 상위 노출 등의 형태로 막연하게 제공됐던 평판을 랭킹이라는 측정 가능한 형태로 바꾸어 제공한다. 아직 출시 전이기 때문에 이후에 변화가 더 있을 수 있다. 그러나 네이버의 랭킹서비스가 성공적으로 안착한다면, 네이버는 포스트-블로그-폴라에서 콘텐츠의 양과 질을 동시에 끌어올릴 수 있을 것으로 보인다.
평판 랭킹, 측정 가능한 형태…
검색엔진 개발과 데이터 분석을 경험한 입장에서 쉽게 이해 되지는 않는다. 12월부터 외부 웹 문서 수집을 더 적극적으로 수용하기 위해 네이버 웹 마스터도구와 신디케이션 업데이트가 이뤄질 예정이란 공지를 했을 때만 하더라도 이제 네이버고 크롤러 기반의 검색엔진 시스템이 시작 되는 것 같다 라는 생각을 했었다.
그런데 지금 이 내용만 놓고 보면(아직 라이브 검색이 오픈 된 상황이 아님으로) 여전히 인력 기반의 검색엔진을 지향한 것 같다는 느낌이다. 라이브 피드백에 대한 공정성이 있을지도 의문이고, 라이브 위드니스 네트워크에 포함되는 팬(친구) 수 집계에서 유령 계정을 어떻게 필터링할 것인지도 의문이다.
라이브 검색이 모바일에 적응하기 위해 설계 되었으나 포스트, 블로그, 폴라를 통합한 것에 그친다면 이도 저도 아닌 서비스가 될 수도 있을 것 같다. 기존 포탈을 모바일로 가져 와 억지로 SNS 개념을 이식하는 것 같다. 옆에 붙은 톡톡은 라인인지 카카오톡 대항을 위해 새롭게 추가되는 기능인지 확실치 않으나 심플함이 생명인 모바일에서 너무 많은 것을 추구한 것은 아닐까 우려되기도 한다. 반면에 네이버의 이런 관점이 지금까지 없었던 참신한 서비스로 어필 될지도 모를 일이다.



 (주)유엑스코리아 CEO
Facebook : http://fb.com/zinicap.kr
Official Web : http://uxkorea.com
(주)유엑스코리아 CEO
Facebook : http://fb.com/zinicap.kr
Official Web : http://uxkorea.com 

